Site-Subject Information
For each subject, the EEG data may be collected in different sites. The information related to the site where the subject’s EEG data was collected is provided on LORIS.
AWS and Cyberduck
MRI and EEG data, organized into folders by participant, may also be accessed through an Amazon Web Services (AWS) S3 bucket.
Each file in the S3 bucket can only be accessed using HTTP (i.e., no ftp or scp ). You can obtain a URL for each desired file and then download it using an HTTP client such as a web browser, wget, or curl. Each file can only be accessed using its literal name- wildcards will not work.
There are file transfer programs that can handle S3 natively and will allow you to navigate through the data using a file browser. Cyberduck is one such program that works with Windows and Mac OS X. Cyberduck also has a command line version that works with Windows, Mac OS X, and Linux. Instructions for using Cyberduck are as follows:
- Open Cyberduck and click on Open Connection.
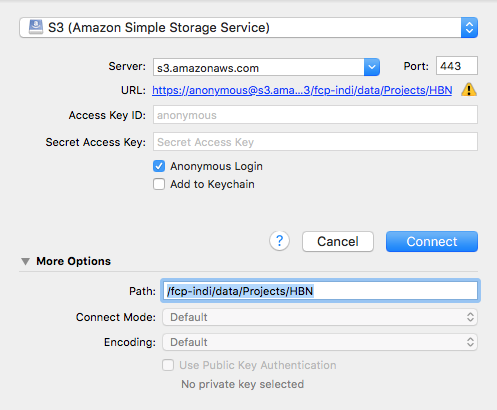
- Set the application protocol in the dropdown menu to S3 (Amazon Simple Storage Service).
- Set the server to s3.amazonaws.com.
- Check the box labelled Anonymous Login.
- Expand the More Options tab
- To access compressed files (.tar.gz), set Path to fcp-indi/data/Archives/HBN
- To access uncompressed files, set Path to fcp-indi/data/Projects/HBN
- Click Connect.
The end result should appear as follows: